Welcome! My name is Robin Chan and I am a machine learning researcher at the Bielefeld University and the Technische Universität Berlin in Germany. Currently, I am also a visiting researcher at the École Polytechnique Fédérale de Lausanne.
My main research interest lies in developing methods for safe AI, in particular for computer vision in the context of automated driving. I am mainly focussing on detection techniques of unknown objects in semantic segmentation.
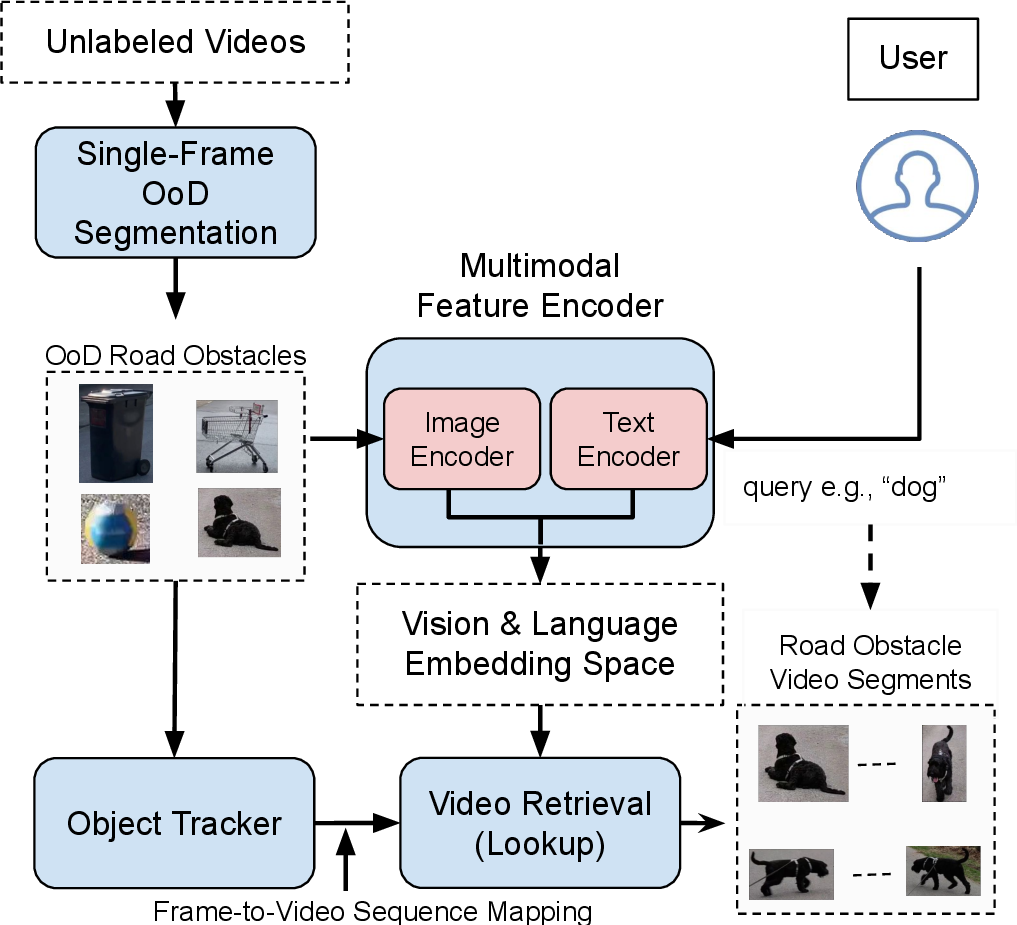
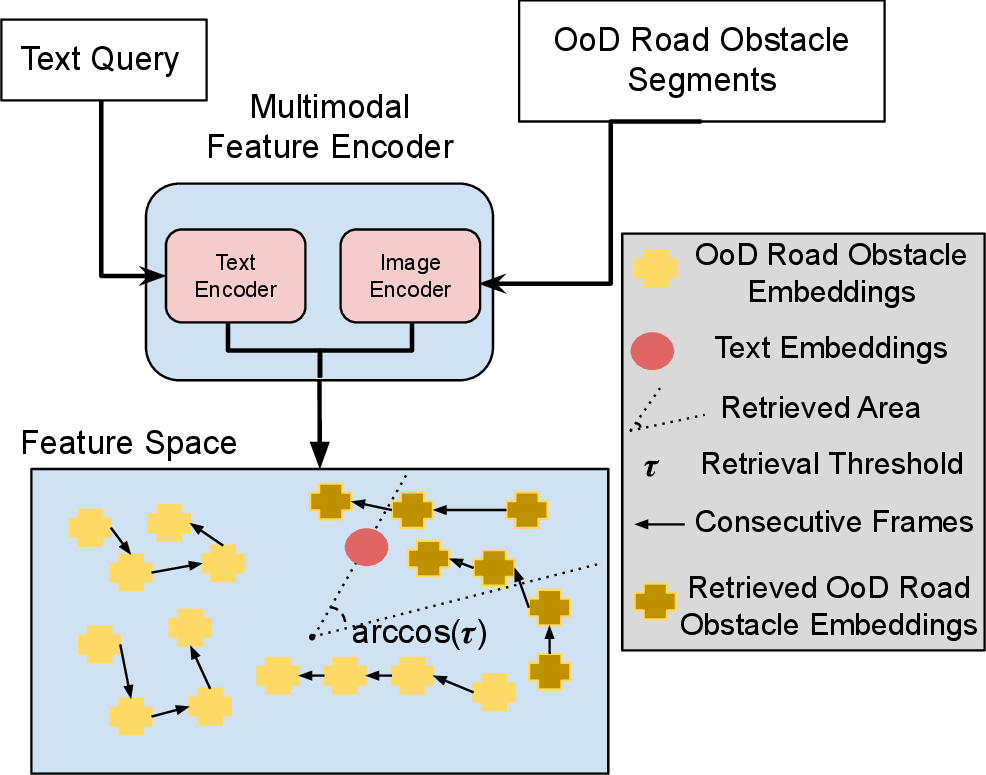
Abstract. In the life cycle of highly automated systems operating in an open and dynamic environment, the ability to adjust to emerging challenges is crucial. For systems integrating data-driven AI-based components, rapid responses to deployment issues require fast access to related data for testing and reconfiguration. In the context of automated driving, this especially applies to road obstacles that were not included in the training data, commonly referred to as out-of-distribution (OoD) road obstacles. Given the availability of large uncurated recordings of driving scenes, a pragmatic approach is to query a database to retrieve similar scenarios featuring the same safety concerns due to OoD road obstacles. In this work, we extend beyond identifying OoD road obstacles in video streams and offer a comprehensive approach to extract sequences of OoD road obstacles using text queries, thereby proposing a way of curating a collection of OoD data for subsequent analysis. Our proposed method leverages the recent advances in OoD segmentation and multi-modal foundation models to identify and efficiently extract safety-relevant scenes from unlabeled videos. We present a first approach for the novel task of text-based OoD object retrieval, which addresses the question ''Have we ever encountered this before?''.
Published in The IEEE Winter Conference on Applications of Computer Vision (WACV) 2024. Available: https://arxiv.org/abs/2309.04302




Abstract. LU-Net is a simple and fast architecture for invertible neural networks (INN) that is based on the factorization of quadratic weight matrices A=LU, where L is a lower triangular matrix with ones on the diagonal and U an upper triangular matrix. Instead of learning a fully occupied matrix A, we learn L and U separately. If combined with an invertible activation function, such layers can easily be inverted whenever the diagonal entries of U are different from zero. Also, the computation of the determinant of the Jacobian matrix of such layers is cheap. Consequently, the LU architecture allows for cheap computation of the likelihood via the change of variables formula and can be trained according to the maximum likelihood principle. In our numerical experiments, we test the LU-Net architecture as generative model on several academic datasets. We also provide a detailed comparison with conventional invertible neural networks in terms of performance, training as well as run time.
Published in The IEEE International Joint Conference on Neural Networks (IJCNN) 2023. Available: https://arxiv.org/abs/2302.10524


Abstract. Deep neural networks (DNN) have made impressive progress in the interpretation of image data, so that it is conceivable and to some degree realistic to use them in safety critical applications like automated driving. From an ethical standpoint, the AI algorithm should take into account the vulnerability of objects or subjects on the street that ranges from "not at all", e.g. the road itself, to "high vulnerability" of pedestrians. One way to take this into account is to define the cost of confusion of one semantic category with another and use cost-based decision rules for the interpretation of probabilities, which are the output of DNNs. However, it is an open problem how to define the cost structure, who should be in charge to do that, and thereby define what AI-algorithms will actually "see". As one possible answer, we follow a participatory approach and set up an online survey to ask the public to define the cost structure. We present the survey design and the data acquired along with an evaluation that also distinguishes between perspective (car passenger vs. external traffic participant) and gender. Using simulation based F-tests, we find highly significant differences between the groups. These differences have consequences on the reliable detection of pedestrians in a safety critical distance to the self-driving car. We discuss the ethical problems that are related to this approach and also discuss the problems emerging from human-machine interaction through the survey from a psychological point of view. Finally, we include comments from industry leaders in the field of AI safety on the applicability of survey based elements in the design of AI functionalities in automated driving.
Published in AI and Ethics. Available: https://arxiv.org/abs/2206.04776 Website: https://uni-w.de/1hx

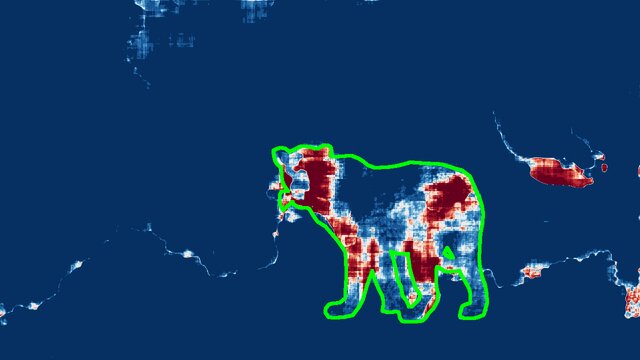
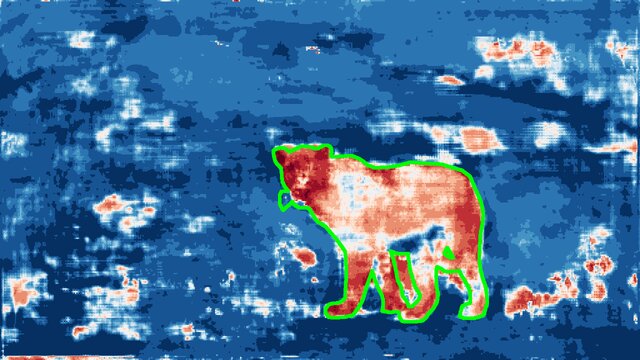

Abstract. State-of-the-art semantic or instance segmentation deep neural networks (DNNs) are usually trained on a closed set of semantic classes. As such, they are ill-equipped to handle previously-unseen objects. However, detecting and localizing such objects is crucial for safety-critical applications such as perception for automated driving, especially if they appear on the road ahead. While some methods have tackled the tasks of anomalous or out-of-distribution object segmentation, progress remains slow, in large part due to the lack of solid benchmarks; existing datasets either consist of synthetic data, or suffer from label inconsistencies. In this paper, we bridge this gap by introducing the "SegmentMeIfYouCan" benchmark. Our benchmark addresses two tasks: Anomalous object segmentation, which considers any previously-unseen object category; and road obstacle segmentation, which focuses on any object on the road, may it be known or unknown. We provide two corresponding datasets together with a test suite performing an in-depth method analysis, considering both established pixel-wise performance metrics and recent component-wise ones, which are insensitive to object sizes. We empirically evaluate multiple state-of-the-art baseline methods, including several specifically designed for anomaly / obstacle segmentation, on our datasets as well as on public ones, using our benchmark suite. The anomaly and obstacle segmentation results show that our datasets contribute to the diversity and challengingness of both dataset landscapes.
Published in The Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track 2021. Available: https://arxiv.org/abs/2104.14812 Website: https://segmentmeifyoucan.com Video: https://slideslive.com/38969495
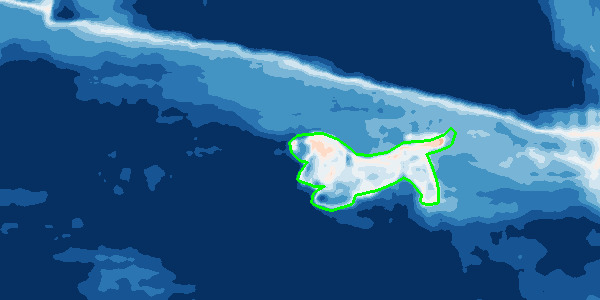

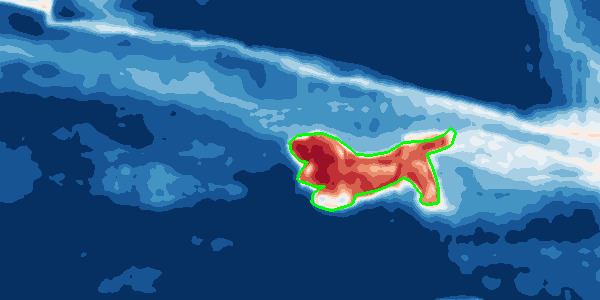

Abstract. Deep neural networks (DNNs) for the semantic segmentation of images are usually trained to operate on a predefined closed set of object classes. This is in contrast to the "open world" setting where DNNs are envisioned to be deployed to. From a functional safety point of view, the ability to detect so-called "out-of-distribution" (OoD) samples, i.e., objects outside of a DNN's semantic space, is crucial for many applications such as automated driving. A natural baseline approach to OoD detection is to threshold on the pixel-wise softmax entropy. We present a two-step procedure that significantly improves that approach. Firstly, we utilize samples from the COCO dataset as OoD proxy and introduce a second training objective to maximize the softmax entropy on these samples. Starting from pretrained semantic segmentation networks we re-train a number of DNNs on different in-distribution datasets and consistently observe improved OoD detection performance when evaluating on completely disjoint OoD datasets. Secondly, we perform a transparent post-processing step to discard false positive OoD samples by so-called "meta classification". To this end, we apply linear models to a set of hand-crafted metrics derived from the DNN's softmax probabilities. In our experiments we consistently observe a clear additional gain in OoD detection performance, cutting down the number of detection errors by up to 52% when comparing the best baseline with our results. We achieve this improvement sacrificing only marginally in original segmentation performance. Therefore, our method contributes to safer DNNs with more reliable overall system performance.
Published in The IEEE/CVF International Conference on Computer Vision (ICCV) 2021. Available: https://arxiv.org/abs/2012.06575. Video: https://youtu.be/jy1i5nKH3ps. Slides: https://uni-w.de/alf7s




Abstract. In semantic segmentation datasets, classes of high importance are oftentimes underrepresented, e.g., humans in street scenes. Neural networks are usually trained to reduce the overall number of errors, attaching identical loss to errors of all kinds. However, this is not necessarily aligned with human intuition. For instance, an overlooked pedestrian seems more severe than an incorrectly detected one. One possible remedy is to deploy different decision rules by introducing class priors that assign more weight to underrepresented classes. While reducing the false negatives of the underrepresented class, at the same time this leads to a considerable increase of false positive indications. In this work, we combine decision rules with methods for false positive detection. We therefore fuse false negative detection with uncertainty based false positive meta classification. We present the efficiency of our method for the semantic segmentation of street scenes on the Cityscapes dataset based on predicted instances of the 'human' class. In the latter we employ an advanced false positive detection method using uncertainty measures aggregated over instances. We thereby achieve improved trade-offs between false negative and false positive samples of the underrepresented classes.
Published in The IEEE International Joint Conference on Neural Networks (IJCNN) 2020. Available: https://arxiv.org/abs/1912.07420


Abstract. We present a method that "meta" classifies whether seg-ments predicted by a semantic segmentation neural network intersect with the ground truth. For this purpose, we employ measures of dispersion for predicted pixel-wise class probability distributions, like classification entropy, that yield heat maps of the input scene's size. We aggregate these dispersion measures segment-wise and derive metrics that are well-correlated with the segment-wise IoU of prediction and ground truth. This procedure yields an almost plug and play post-processing tool to rate the prediction quality of semantic segmentation networks on segment level. This is especially relevant for monitoring neural networks in online applications like automated driving or medical imaging where reliability is of utmost importance. In our tests, we use publicly available state-of-the-art networks trained on the Cityscapes dataset and the BraTS2017 dataset and analyze the predictive power of different metrics as well as different sets of metrics. To this end, we compute logistic LASSO regression fits for the task of classifying IoU=0 vs. IoU>0 per segment and obtain AUROC values of up to 91.55%. We complement these tests with linear regression fits to predict the segment-wise IoU and obtain prediction standard deviations of down to 0.130 as well as R^2 values of up to 84.15%. We show that these results clearly outperform standard approaches.
Published in The IEEE International Joint Conference on Neural Networks (IJCNN) 2020. Available: https://arxiv.org/abs/1811.00648

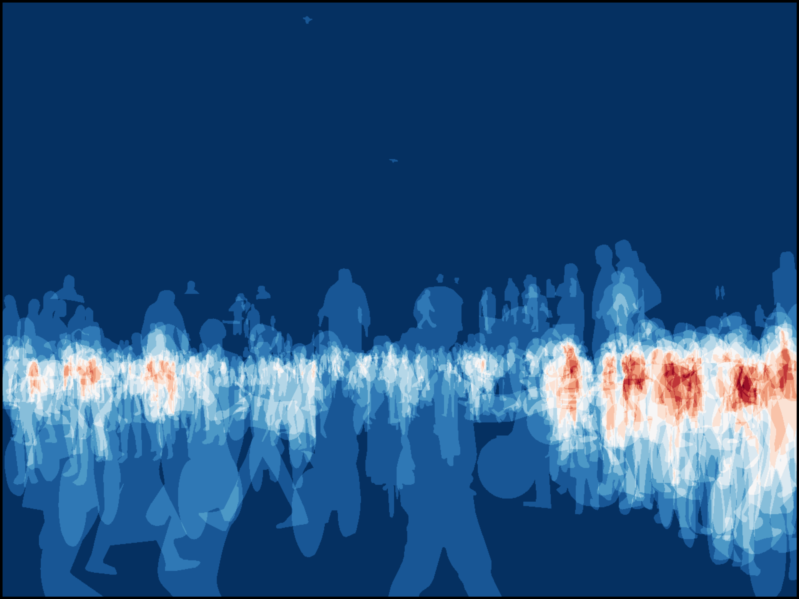
Abstract. As part of autonomous car driving systems, semantic segmentation is an essential component to obtain a full understanding of the car's environment. One difficulty, that occurs while training neural networks for this purpose, is class imbalance of training data. Consequently, a neural network trained on unbalanced data in combination with maximum a-posteriori classification may easily ignore classes that are rare in terms of their frequency in the dataset. However, these classes are often of highest interest. We approach such potential misclassifications by weighting the posterior class probabilities with the prior class probabilities which in our case are the inverse frequencies of the corresponding classes in the training dataset. More precisely, we adopt a localized method by computing the priors pixel-wise such that the impact can be analyzed at pixel level as well. In our experiments, we train one network from scratch using a proprietary dataset containing 20,000 annotated frames of video sequences recorded from street scenes. The evaluation on our test set shows an increase of average recall with regard to instances of pedestrians and info signs by 25% and 23.4%, respectively. In addition, we significantly reduce the non-detection rate for instances of the same classes by 61% and 38%.
Published in The 30th European Safety and Reliability Conference (ESREL) 2020. Available: https://arxiv.org/abs/1901.08394


Abstract. Neural networks for semantic segmentation can be seen as statistical models that provide for each pixel of one image a probability distribution on predefined classes. The predicted class is then usually obtained by the maximum a-posteriori probability (MAP) which is known as Bayes rule in decision theory. From decision theory we also know that the Bayes rule is optimal regarding the simple symmetric cost function. Therefore, it weights each type of confusion between two different classes equally, e.g., given images of urban street scenes there is no distinction in the cost function if the network confuses a person with a street or a building with a tree. Intuitively, there might be confusions of classes that are more important to avoid than others. In this work, we want to raise awareness of the possibility of explicitly defining confusion costs and the associated ethical difficulties if it comes down to providing numbers. We define two cost functions from different extreme perspectives, an egoistic and an altruistic one, and show how safety relevant quantities like precision / recall and (segment-wise) false positive / negative rate change when interpolating between MAP, egoistic and altruistic decision rules.
Published in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops 2019. Available: https://arxiv.org/abs/1907.01342
École Polytechnique Fédérale de Lausanne | School of Computer and Communication Sciences | Computer Vision Laboratory | Lausanne, Switzerland
Technische Universität Berlin | Institute of Mathematics | Mathematical Modeling of Industrial Life Cycles | Berlin, Germany
Bielefeld University | Faculty of Technology | Machine Learning Group | Funded by the Ministry of Culture and Science of the German State of North Rhine-Westphalia | Out-of-Distribution Detection via Generative Modeling of Deep Latent Representations | Bielefeld, Germany
University of Wuppertal | School of Mathematics and Natural Sciences | Stochastics Group | Funded by German Federal Ministry for Economic Affairs and Energy | KI Absicherung – Safe AI for Automated Driving | Wuppertal, Germany
University of Wuppertal | School of Mathematics and Natural Sciences | Applied Computer Science Group | Funded by Volkswagen Group Research | Wuppertal, Germany
Volkswagen Group Research | Automated Driving | Architecture and AI Technologies | Wolfsburg, Germany
University of Wuppertal | Mathematics for Economy Scientists | Mathematics for Civil Engineers | Wuppertal, Germany
Siemens AG | Energy Sector | Large Gas Turbine Engineering | Probabilistic Design | Berlin, Germany
Mathematics | Doctor of Natural Sciences | University of Wuppertal
Mathematics | Master of Science | University of Wuppertal
Mathematical Economics | Bachelor of Science | University of Wuppertal




